(前回の Reasoning Gate の活用について考えていたら以下のアイデアを思いついたので掲載する。ただ、すこし思想寄りになったのとブログ用に丁寧語になっているのが気に入らない人もいるかも。scaffolding を用いた説明は ChatGPT が思いついた)
1 高知能との対話
一般に「IQ が 20 違うと問題の設定・前提・重要度の置き方がずれて会話がかみ合わなくなる」ということが言われています。実際に最近の LLM と対話していると圧倒的な知識量とその知識からの推論によりその正しさが絶対的に思えてしまうことがあるかもしれません。
ただし、専門的な目から見ると一貫性のない回答だったり、推論の誤り等もあり LLM との対話ではそういった点を見抜く必要があります。また、LLM との対話は言語を通して行われるため、言語能力が発展途上である子供などには理解が難しいという点もあります。
1.1 LLM を使いこなすために
このように LLM の知能が高くなることにより LLM を使いこなせる人たちは限られてきます。
そして、現在、LLM の開発はより賢くより効率的に問題を解決できるように開発が進められており、この LLM と人の知能のギャップに対して何らかの解決方法がなければ取り残される人々が出てきてしまいます。
2 LLM は"考えすぎている"のか?
Chain-of-Thought では LLM に明示的に推論を出力させることで問題解決能力を高める手法です。これがなぜ効果的かというと、考え方を書かせると LLM が正しく考えられるからです。
この点が本当にそうなのか?つまり、もしそうなら考え方を書くことを禁止した瞬間に LLM は全く考えられなくなるはずです。
2.1 LLM の思考の禁止に関する実験
そこで次の算術推論に関する実験を行いました。
- 通常の few-shot prompt
- そこに 「Do NOT show your reasoning steps」を追加
つまり、「考えるな、答えだけを出せ」と指示を行い実験を行いました。そして結果は次の通りでした。
- GPT-3.5: 正答率が約 80 % $\to$ 約 30 %
- GPT-4o: 正答率が約 90 % $\to$ 約 50 %
特筆すべき点は GPT-4o でも正答率が 50 % と半分以上正しく答えられています。算術推論の問題であり正しく答えるためには推論が必須な問題においてです。
2.2 実験結果からの示唆
この結果は次の可能性を示唆しています。
GPT-4o は「考え方を書いていないだけで、内部では考えているのではないか?」
つまりここで起きているのは推論の出力を禁止しても
- 「考えていない」のではなく
- 「考えているが、それを外に出していない」
という可能性があります。そして
GPT-3.5 では推論を外に出させないと性能が大きく崩れ
- GPT-4o では外に出さなくてもある程度正しく解けています
ここまでの結果を見ると、LLM の推論には少なくとも次のような状態がありそうです。
- 推論を完全に止めている状態
- 推論はしているが、外には出していない状態
- 推論をそのまま外に出している状態
次の章で、これらの 「推論の抑制」、「暗黙的推論」、「明示的推論」という3つの状態として整理します。
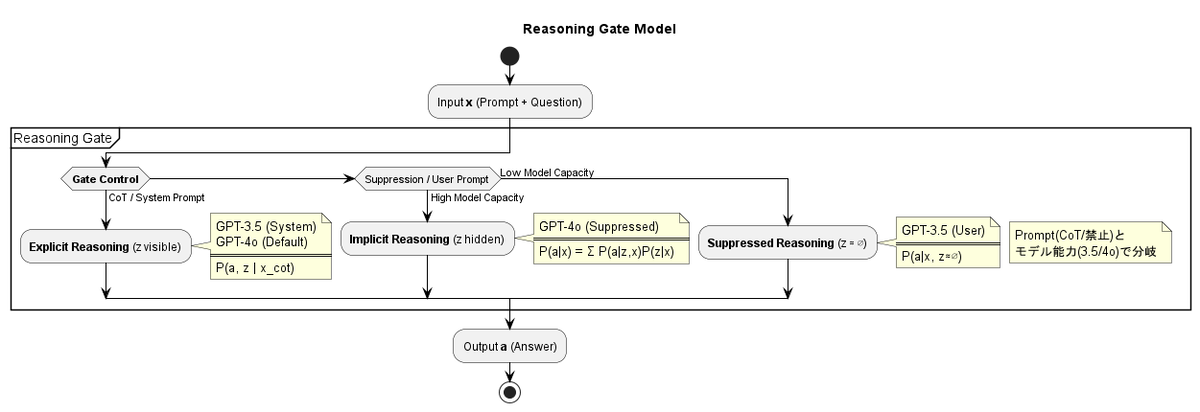
2.3 推論の3つの状態
前章から推論の3つの状態が存在している可能性を示唆しました。これらは
- Suppressed reasoning (推論の抑制)
- Implicit reasoning (暗黙的推論)
- Explicit reasoning (明示的推論)
となり、1. 推論の抑制は推論を禁止し LLM に出力させる、つまり、推論はせず直感的に出力させるモード、2. 暗黙的推論は LLM のモデルの内部だけで推論させるつまり頭の中だけで推論を行うモード、3. 明示的推論は推論を出力させるて答えを導く、つまり、紙に推論、考え方を記述しながら答えを求めるモードと直感的に説明できます。
2.4 prompt による推論の状態の制御
このような LLM の推論の仕方は prompt で制御が可能と思われ、これまで prompt は LLM の出力の仕方を制御するものと思われていましたが、上記のような推論の状態を制御している可能性があります。このような推論の状態の制御について次の章で整理します。
3 Reasoning Gate : LLM の知能の制御の仕組み
前章では、LLM の推論には少なくとも 3 つの状態が存在する可能性を示しました。
- 推論を完全に止めている状態
- 推論をしているが、外には出していない状態
- 推論をそのまま外に出している状態
重要なのはこれらが別々のモデルや能力ではなく、同一の LLM の中で切り替わっている点です。
3.1 推論はどれを使うかが重要
これまでは LLM に対してより賢いか?より複雑な推論できるか?という観点から LLM を評価してきました。
しかし、これまでの実験結果を見るとより正確なのは次の問いです。
LLM は今、どの推論モードを使っているのか?
つまり、能力の有無ではなく、選択の問題と考えられます。
3.2 prompt は出力ではなく知能の使い方を選んでいる
これまで prompt は
- 出力形式を整えるもの
- 口調や役割を指定するもの
として理解されてきました。しかし、今回の結果から prompt はそれ以上の役割を持っていることが分かります。
- 推論を書かせる prompt
明示的推論モード
- 推論を禁止する prompt
- 推論を指定しないが few-shot を与える
つまり prompt は、LLM の「どの知能の使い方を有効にするか」を選択しているととらえることができます。
3.3 Reasoning Gate という見方
このように、prompt によって推論の状態が切り替わる仕組みをこのブログでは Reasoning Gate と呼んでいます。
Reasoning Gate とは、
LLM の内部に存在する複数の推論モードのうち、どれを使うか制御するゲート
そのため
- ゲートを閉じると推論は抑制され、即答に近いふるまいになる
- 半開にすると推論は内部で行われるが外に出ない
- 全開にすると推論がそのまま言語として出力される
このゲートはモデルの外部つまり prompt によって操作可能となります。
3.4 GPT-3.5 と GPT-4o で何が違うのか
ここで、GPT-3.5 と GPT-4o の違いを Reasoning Gate の観点から整理します。
- GPT-3.5
- デフォルトではゲートが閉じ気味
- system-level の few-shot によって初めて安定して開く
- 推論を禁止すると、ほぼ完全に性能が崩れる
- GPT-4o
- デフォルトでゲートが半開〜全開
- 推論を禁止しても、完全には閉じない
- 内部推論が常在している可能性が高い
これは、GPT-4o では推論が 一時的な振る舞いではなく、内部表現として定着している ことを示唆しています。
3.5 知能を制御できると何が嬉しいのか
ここで話を冒頭の「高知能との対話」に戻します。 LLM が賢くなればなるほど、
- 推論が深くなる
- 抽象度が高くなる
- 人間との知能ギャップが広がる
という問題が生じます。
Reasoning Gate の考え方は、この問題に対して次の視点を与えます。
知能は高ければ良いのではなく、
調整できて初めて使いこなせる
推論をあえて抑制する、
推論を外に出させる、
あるいは内部に任せる。
これらを意識的に切り替えることで、
LLM は「賢すぎて扱いづらい存在」から
対話可能な知能へと変わります。
4. 知能の制御ができると LLM は使いやすくなる
LLM の知能を制御することで以下の3つの場面が考えられます。
- 推論を抑制した方が良い場面
- 明示的推論が必要な場面
- 暗黙的推論に任せる場面
推論を抑制したほうがいい場面
これは論理的な結論が必要な場面ではなくブレインストーミングなどのいろいろなアイデアが必要なケースで必要となります。また、ほかにも日常会話等でも推論が必要ない場面が多くあります。
明示的推論が必要な場面
これは解決のための推論が複雑になるケースで重要であり、その推論過程も含めて正しさを検証することが可能です。専門家の問題解決タスクでは解法だけでなくその判断に至った過程も重要であり明示的推論が必要になります。
暗黙的推論が必要な場面
これは問題解決のために推論は必要だが、複雑な推論は必要ないケースで有用となります。暗黙的推論により LLM の推論コストを削減することが可能となります。
以上のように 知能は高ければ良いのではなく、調整して使えるという点が重要と考えられます。
5. LLM を「訓練」するのではなく「対話を訓練する」
また、子供などの言語的能力が発展途上の場合において LLM の知能を制御し対話を行い、徐々に行動な対話へと移行することで LLM との対話能力を伸ばしていく必要もあります。これにより子供のうちから LLM との対話を通して言語能力を育てていきより高度な知性を育てていくことにつながります。
人間側のスキルとしての prompt
これまで prompt は、 「うまく書ける人だけが使える特殊な技術」 のように語られることが多くありました。 しかし、Reasoning Gate の観点から見ると、prompt はまったく別の意味を持ちます。 prompt とは、 LLM に対して「どの知能モードを使ってほしいか」を伝える対話スキル です。
これは人間同士のコミュニケーションと非常によく似ており
- 相手にすべて考えさせるのか
- 途中の考え方を説明してもらうのか
- 結論だけを端的に求めるのか
私たちは日常的に、相手の理解度や状況に応じてこれらを使い分けています。 LLM との prompt も本質的には同じです。
つまり、prompt とは LLM を操作するコマンドではなく、
知能差のある相手と会話するためのスキル だと捉えることができます。
scaffolding(足場かけ)としての推論外部化
教育心理学には scaffolding(足場かけ) という概念があります。
これは、学習者が自力では到達できない課題に対して、
- 途中の手順を示す
- 分解して考えさせる
- 必要な部分だけ支援する
といった「一時的な支え」を与え、
徐々にその支えを外していく手法です。
Chain-of-Thought による推論の外部化は、
この scaffolding と極めてよく似ています。
- 推論を書かせる
- 人間はその推論を確認し、理解し、修正できる
- LLM 側も推論の誤りを検出しやすくなる
この段階では、 あえて推論を外に出させることが重要です。 それは LLM のためだけでなく、 人間側が LLM の思考に追いつくためでもあります。
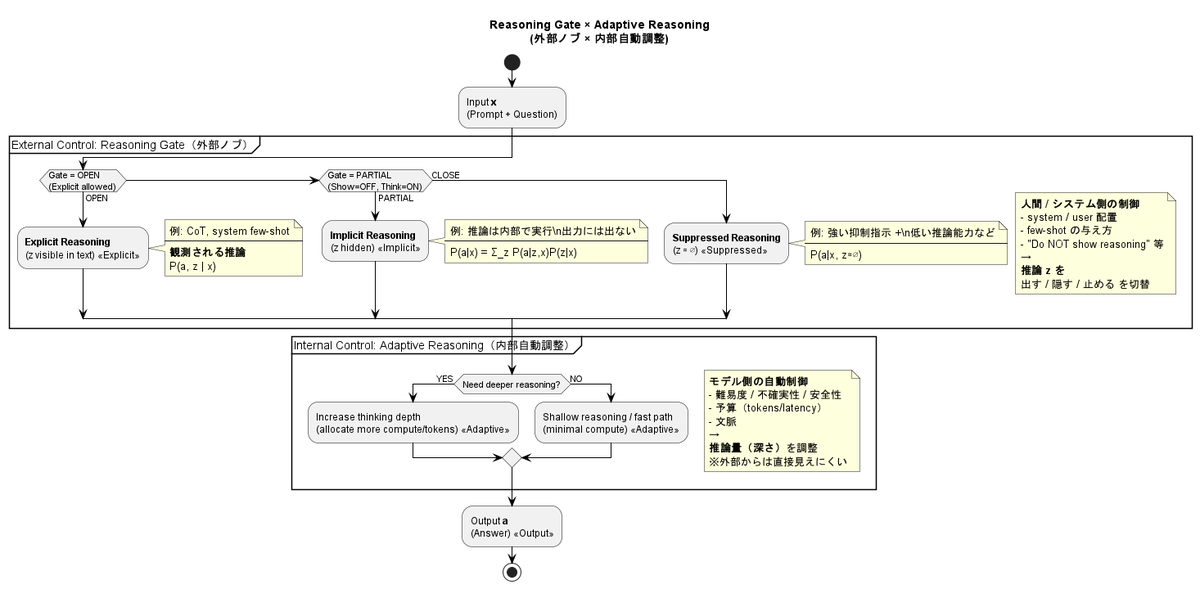
補足:Adaptive Reasoning との違い
ここまで、prompt や推論外部化を通じて
人間側が LLM の推論を調整していく という考え方を述べてきました。
一方で、最近の LLM では Adaptive Reasoning と呼ばれる仕組みが導入されています。
Adaptive Reasoning とは、 LLM 自身が問題の難易度や状況を判断し、
- 深く考えるべきか
- 簡潔に答えるべきか
- 推論をどの程度行うか
を 内部で自動的に調整する 仕組みです。
一見すると、 「それなら人間が prompt を工夫する必要はないのでは?」 と思うかもしれません。 しかし、ここには重要な違いがあります。
Adaptive Reasoning は、 LLM が自分自身の効率や安定性を最適化するための仕組み です。
一方で、これまで述べてきた Reasoning Gate の考え方は、
人間と LLM の知能ギャップをどう埋めるか
という問題を扱っています。
Adaptive Reasoning が解決しようとしているのは、
- 計算コスト
- 応答速度
- 安全性
といった モデル内部の最適化 です。
それに対して Reasoning Gate は、
- 人間が理解できるか
- 学習・成長につながるか
- 対話が成立しているか
という 人間中心の問題 を扱います。
このため、Adaptive Reasoning が存在しても、
- 推論を外に出して理解したい場面
- 思考過程を確認・修正したい場面
- 教育的に段階的な対話を行いたい場面
では、依然として 人間側からの制御 が重要になります。
重要なのは、
Adaptive Reasoning と Reasoning Gate は 競合する概念ではない
という点です。
Adaptive Reasoning は
Reasoning Gate の「内側」で動作する内部最適化であり、
- どの推論モードを使うか(Reasoning Gate)
- その中でどれだけ考えるか(Adaptive Reasoning)
という 階層構造 として捉えることができます。
徐々に暗黙化する使い方
また、scaffolding は 永続的なものではない という点です。
学習が進めば、
途中式を書かなくても答えが分かるようになります。
LLM との対話も同様です。
- 最初は推論を明示的に出させる
- 推論のパターンや癖を理解する
- 正しさを検証できるようになる
- 徐々に推論を内部に任せる
このようにして、
推論は 明示的 → 暗黙的 へと移行していきます。
GPT-4o のようなモデルでは、
この暗黙的推論がすでに内部表現として安定しているため、 必ずしも毎回推論を外に出させる必要はありません。
しかし、それは推論を理解し、信頼できる段階に到達しているからこそ可能 だと言えます。
6 AI Agent への示唆:知能を動的に切り替える
ここまでの議論から、重要な結論がひとつ導かれます。
AI Agent は、常に「賢く考える」べきではない
という点です。
これは直感に反するかもしれません。
しかし、これまで見てきた実験結果と Reasoning Gate の考察を踏まえると、
むしろこちらの方が自然な結論です。
Agent は常に推論すべきではない
Chain-of-Thought や高性能 LLM の登場以降、
- できるだけ深く考えさせる
- できるだけ賢いモデルを使う
- できるだけ推論を引き出す
ことが「良い Agent」だと考えられがちでした。
しかし実際には、
- 単純なタスク
- 明確なルールがある処理
- すでに答えがほぼ決まっている場面
においてまで、
重い推論を回す必要はありません。
むしろそのような場面で推論を行うと、
- 応答が遅くなる
- コストが増える
- 誤った一般化や過剰な説明が発生する
といった問題が起こります。
これは人間でも同じです。
- 毎回、足し算を論理的に証明し直す人はいない
- 慣れた作業では「考えずに」動く
- 必要な場面だけ、深く考える
AI Agent も同様に、
「考える/考えない」を切り替える存在であるべきです。
状況・ユーザ・コストに応じて切り替える
では、何を基準に切り替えるべきでしょうか。
本記事で導入した Reasoning Gate の考え方を使うと、
次の3つの軸が浮かび上がります。
1. 状況(タスクの性質)
- 定型処理 → 推論を抑制
- 探索・設計・分析 → 明示的推論
- 曖昧だが経験則が使える → 暗黙的推論
2. ユーザ(理解度・目的)
- 初学者・教育用途 → 推論を外部化
- 熟練者・高速作業 → 暗黙的推論
- 意思決定責任がある場面 → 明示的推論
3. コスト(時間・計算・安全性)
- 低レイテンシ重視 → 推論を抑制
- 品質重視 → 推論を許可
- 不確実性が高い → 推論を拡張
ここで重要なのは、
これらはすべて動的に変わるという点です。
つまり Agent に求められるのは、
「常に賢いこと」ではなく
「賢さの出し方を切り替えられること」
です。
Adaptive Reasoning Agent という方向性
この文脈で見えてくるのが
Adaptive Reasoning Agent という設計思想です。
これは単に、
- LLM が内部で推論量を調整する(Adaptive Reasoning)
という話ではありません。
それに Reasoning Gate を組み合わせ、
- 推論するかどうか
- 推論を外に出すかどうか
- 推論をどのレベルまで行うか
を、
- タスク
- ユーザ
- 対話の文脈
に応じて 動的に切り替える Agent です。
言い換えると、
Adaptive Reasoning Agent とは
知能を「固定値」ではなく「可変パラメータ」として扱う Agent である
ということです。
人間と AI の関係が変わる
この視点に立つと、
AI Agent は「常に上位知能として振る舞う存在」ではなくなります。
- 教師にもなる
- 生徒にもなる
- 黙って作業する道具にもなる
- 一緒に考えるパートナーにもなる
その切り替えを支えているのが、
- Reasoning Gate(外部からの制御)
- Adaptive Reasoning(内部での最適化)
という 二層構造 です。
次に来る問い
最後に、自然と次の問いが浮かびます。
では、人間は
どのようにしてこの「知能の切り替え」を使いこなせるようになるのか?
それは LLM を訓練する話ではありません。
人間側の対話能力をどう育てるかという問題です。
この問いに対する答えとして、
本記事で述べてきた
- 推論の外部化
- 足場かけ
- 徐々な暗黙化
というプロセスが、
AI Agent 時代の新しい「学習曲線」になると考えられます。
7. まとめ:LLM の知能は「固定値」ではない
本記事では、Chain-of-Thought を起点として、
- 推論を 抑制・暗黙・明示 の3状態に分類し
- 推論生成が prompt によって制御されうること
- モデルサイズの増大により暗黙的推論が創発すること
- その制御機構を Reasoning Gate として整理できること
を、実験と考察を通して見てきました。
ここで重要なのは、
LLM の知能が「固定された能力」ではないという点です。
同じモデルであっても、
- prompt の置き方
- 推論の許可・禁止
- system / user の条件付け
- モデル内部の適応的推論
によって、
まったく異なる知能レベル・振る舞いを示すことが明らかになりました。
知能を「高くする」から「制御する」へ
これまでの LLM 開発は、
より大きく、より賢く
という方向に進んできました。
しかし本記事の議論が示すのは、
次のフェーズではそれだけでは不十分だということです。
これから重要になるのは、
- どれだけ賢いかではなく
- どの賢さを、いつ、どの程度使うか
という 知能の制御 です。
人間と LLM の関係は変わる
LLM が暗黙的推論能力を獲得したことで、
- 常に説明する教師
- 常に黙って答える計算機
のどちらか一方ではなく、
- 一緒に考える相手
- 思考を肩代わりする存在
- 学習の足場になる存在
として振る舞えるようになりました。 その切り替えを可能にするのが、
- 外部からの Reasoning Gate
- 内部での Adaptive Reasoning
という二層構造です。
LLM を訓練する時代から、対話を訓練する時代へ
最後に強調したいのは、
これから必要なのは
LLM を訓練することではなく、人間側の対話を訓練すること
だという点です。
- 推論を外に出す
- 足場をかける
- 徐々に暗黙化する
というプロセスは、
人間が高度な思考を身につける過程とよく似ています。
LLM はその過程を 拡張・加速する知的インフラ になり得ます。
結論
優れた LLM 活用とは、
知能を最大化することではなく、
知能を調律することである。